

Notes on Informatica Big Data Management with Intelligent Data Lake Deep Dive and Demo
Informatica Big Data Management (BDM)
- Secure/Govern
- Secure & Govern, Connect, Ingest, Parse, Extract, Profile, Process, Perform
- Polyglot Computing
- Informatica Native, Database Pushdown, Hadoop Pushdown, Map Reduce, Tez, Blaze
New trends in big data management:
- Collect Everything
- New User Class
- Data Scientists
- Flexible Access
- Batch, Real-Time, Interactive, On-Premise, Cloud
Challenges Faced by Organization
- IT
- Can’t cope with growing business demands
- No visibility into what the business is doing with the data
- Losing the ability to govern and manage data as an asset
- Data Analysts
- Frustrated by slow response from IT due to long backlog
- Can’t easily find trusted data
- Limited access to the data
- No way to collaborate, share, and update curated datasets
“If you don’t understand the data assets, how do you use them?”
“It’s frustrating to see a really promising dataset only to find out it’s really bad.”
“I need metadata for those data assets, to provide visibility into the data lineage.”
“Too many data silows make it impossible to know what data can be trusted.”
“Prepping & cleaning the data takes us 2-3 weeks, sometimes longer.”
Informatica’s “Intelligent Data Lake”

nformatica’s “Smart Executor” will determine the best execution engine at runtime (Hive, Spark, etc.)
Engine then sends it to the resource manager (YARN) and it goes from there…

SQL to Informatica mapping functionalities
- Complex SQL with multiple JOINs can be converted to mappings (for ETL, it’s an Informatica thing)
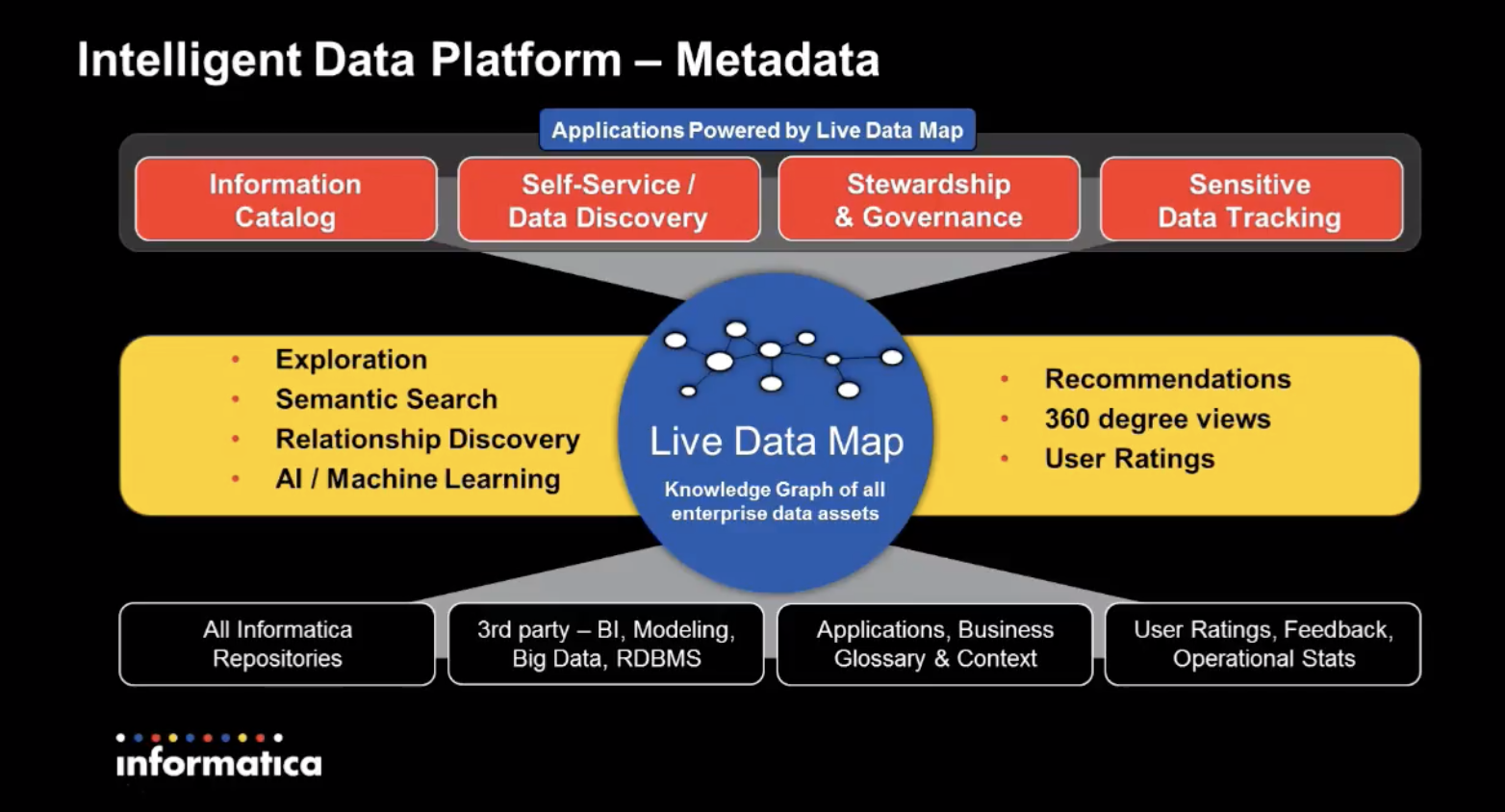
Intelligent Data Platform – Metadata
Enterprise Information Catalog module
- Analyze and understand large volumes of data in an enterprise environment
- Information about data domains, data relationships, etc.
- “Unified view into enterprise information assets”
- Business-user oriented solution
- Semantic search with dynamic facets
- Data lineage
- Change impact
- Relationships discovery
- High level data profiling
- Data domains
- Custom attributes with business classificaitons
- Broad metadata source connectectivity
- Big data scale
Intelligent Data Lake Demo
- Centralized repo of large volumes of structured and unstructured data (a Hadoop cluster)
- Analysts can use a data lake for self-service to discover and prepare data assets with little or no training
- Data lake terminology
- Data Asset – data you work with as a unit
- Project – a container that stores assets and worksheets
- Recipe – The steps taken to prepare data in a worksheet
- Data prep – the process of combining, cleansing, transforming, and structuring data
- Data publication – making the data available in the data lake
- For IT - Data Discovery & Analysis Process
- Analyst searches for assets with “Live Data Map”
- Recommendation engine provides suggestions
- Data Prep application sets up data sets
- These “recipes” can be operationalized/automated
- Publish!
- Uploading data
- From local drive
- “Trending Searches”, Recently Viewed, Asset Types
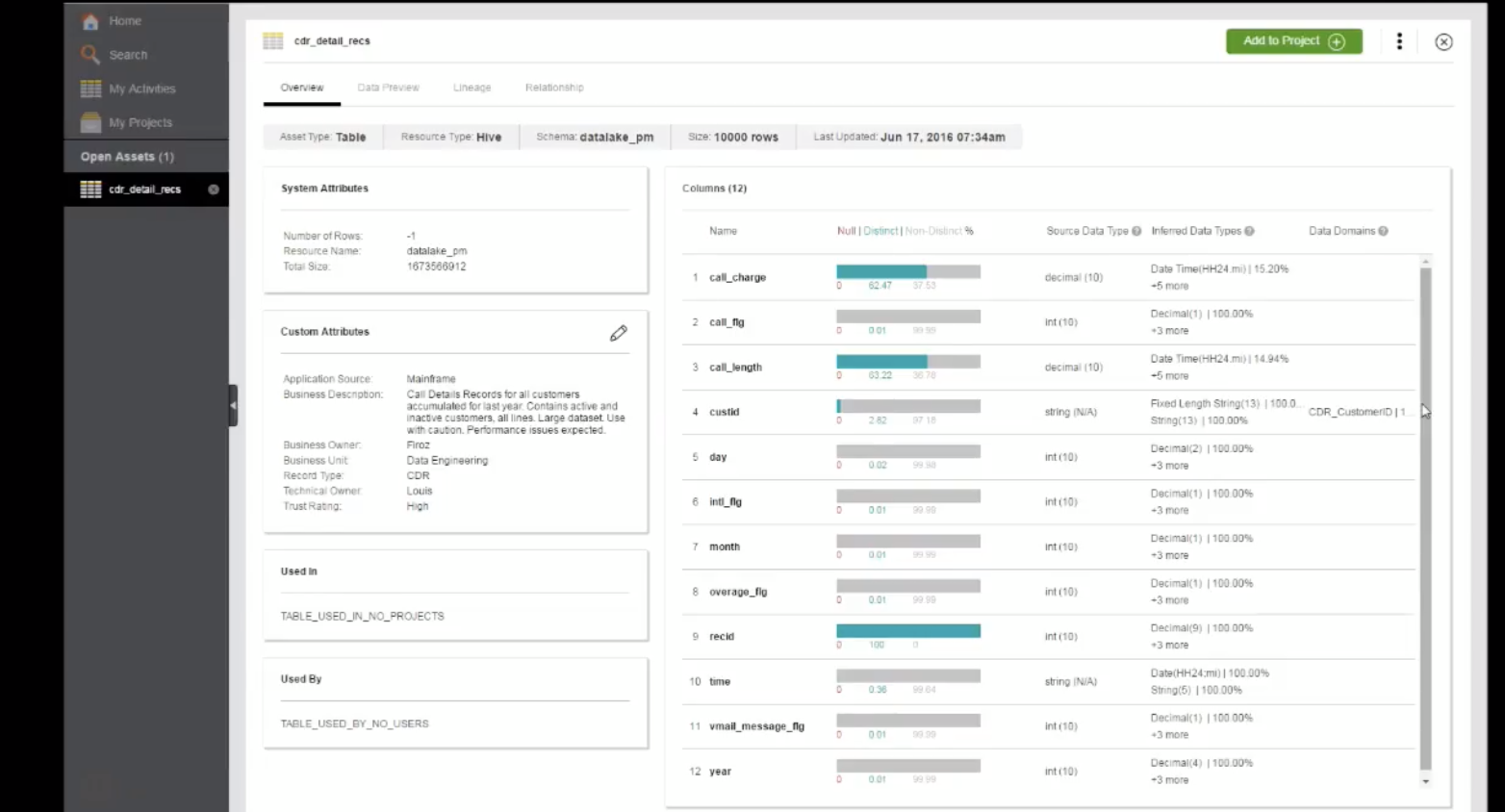
“Lineage” will tell you where it all comes from:

“Relationships” tell you what other tables have a join id

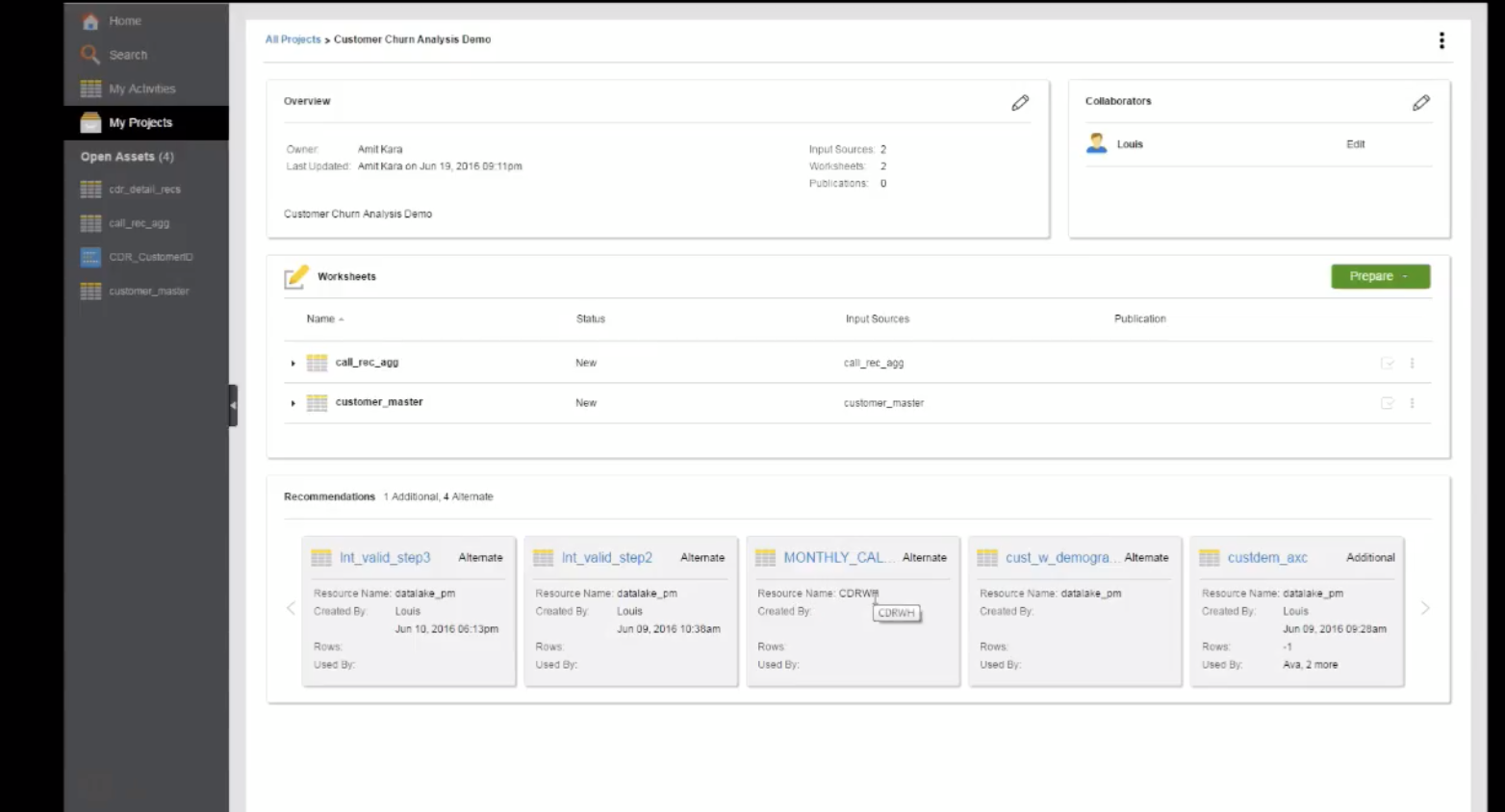
“Recommendations” – Based on data assets added to the project
Blend data by combining worksheets
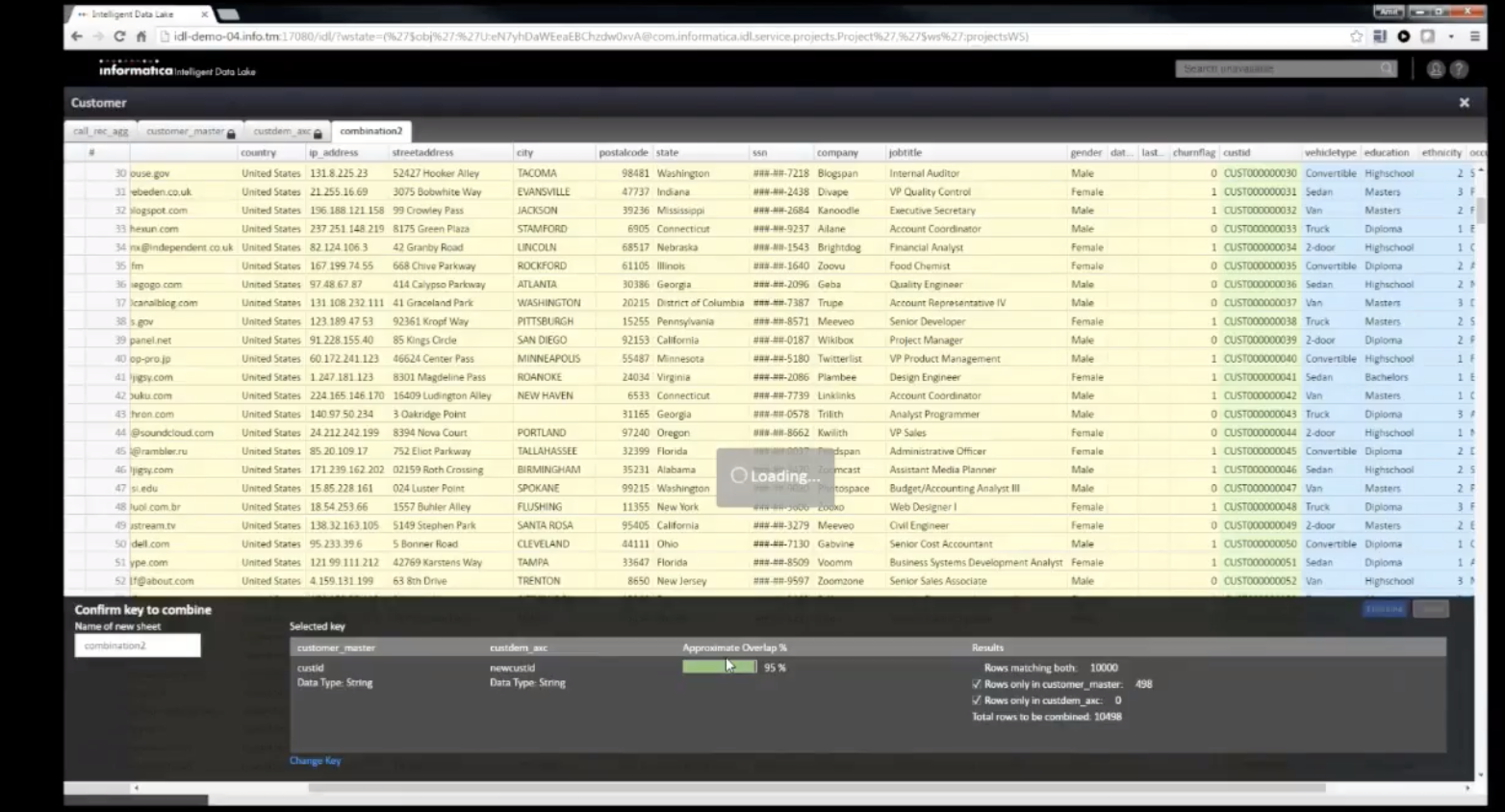
Add formulas, create the new data sets and add it to the project. All of the steps are visible and saved.
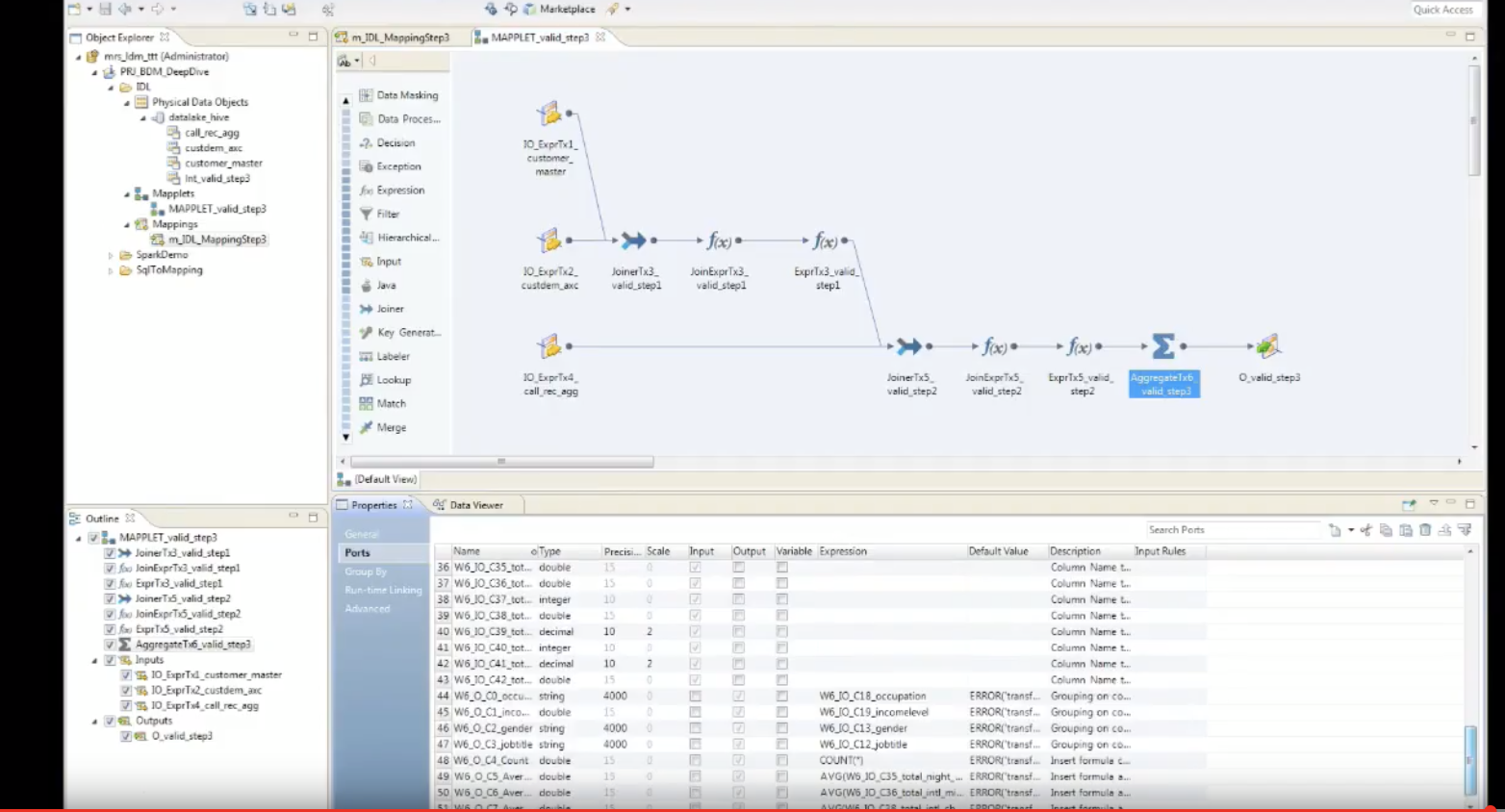
- From here, this mapping can be scheduled to run automatically
Real-time integration with Informatica Cloud REST API (with Salesforce)
Before
- Data sync tasks runs and pulls changes in to systems
After
- Instead of relying on manual/scheduled execution, it can fire based on an event
- Create an Apex trigger.
- Create an apex class that will fire with the trigger
- Realtime update!