
Behind the Code: Using the Data Layer
Notes come from this video:
We want to know about really detailed user behavior.
To do this, requires lots of bits of JavaScript to do stuff with this data
Today, we've got dozens of different services for things like web analytics, conversion tracking, etc., each with their own implementation, "this is how you send me [a service such as track.io] data"

They can break in different ways as the website changes...

This becomes very unmanageable...you don't want global variables for every single one of these vendors!
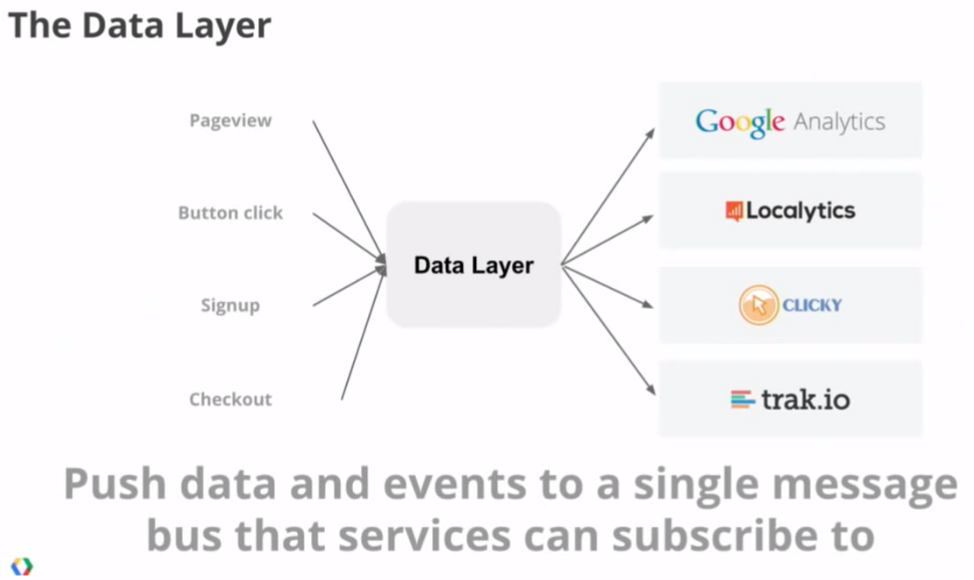
But here's what the Data Layer does–a common message bus that all of these different services can use
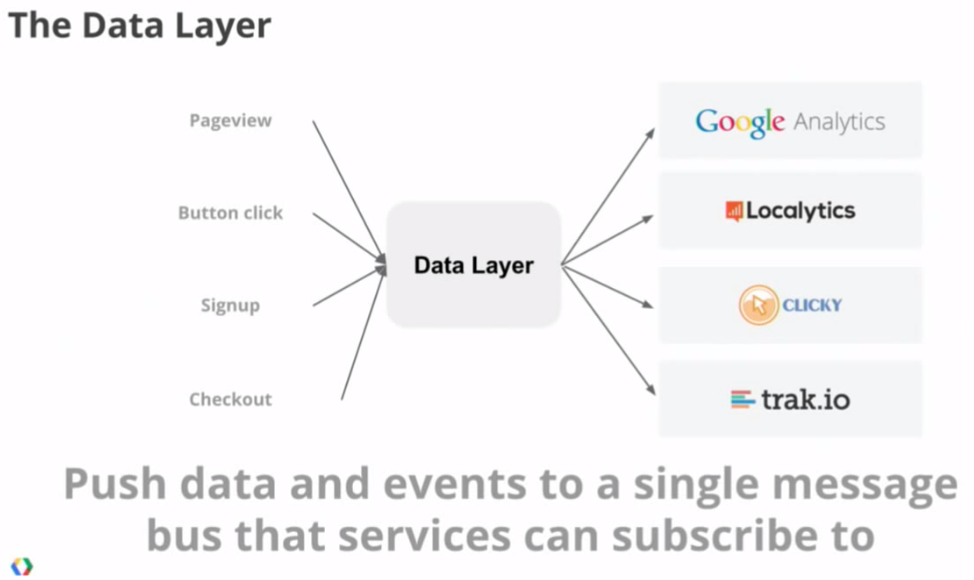
The concern becomes less "how do I interactive with all of these different services" and more "how do I expose the proper data for this page"?
Benefits
- A common, well-defined system for exposing page data
- Doesn't slow down page rendering
- Doesn't pollute the global JavaScript namespace
- Doesn't require page authors to learn a different, one-off API for every new tool
- Doesn't require page authors to expose the same data multile times
- Allows page authors to add/remove or change vendors easily
The Data Layer is a basic JavaScript array, with some conventions around how you use it.

This keeps the page author's job much simpler
Vendors will consume the data as it comes in.
As additional actions on the page occur, you can append stuff to the Data Layer. Example, when a user clicks an item on a carousel:

How do vendors consume Data Layer messages? The abstract data model...
For each message, the page author passes key-value pairs.
There's an in-memory store of the most-recently value for any given key, so the vendor doesn't need to be there at the time of the message.
Data Layer Help in Github, industry standard for subscribing to the Data Layer. Vendors like Fullstory, Pendo, etc., use this standard approach to how data is bused on the page.
In essence, the tags themselves (the vendors) will reference the Data Layer at different points, depending on what needs to be captured for that platform.


Google Tag Manager
Each gtm.js JavaScript code gets customized for each container. Tags (JavaScript snippets such as Pendo, Fullstory, Optimizely, Hotjar, etc.) are added via the GTM console. When published, those tags are added to GTM’s script. Here's an example of a GTM script with other scripts injected.
- Tags are what send the data to analytics platform (GA or others). The JavaScript snippet that talks to analytics platform resides within gtm.js
- When we configure container through GTM UI, adequate tag (JavaScript code) gets added to gtm.js for your container.
That's how tag management products achieve inserting code snippet within sites without needing any alterations to the actual site pages (beyond inserting the initial container tag related code, of course).
DOM loads
- GTM c”ode loads and does it's thing _makes checks _creates dataLayer object _invokes gtm.js library (loads it whole in the browser) _pushes basic objects into dataLayer _"imports" tags, triggers and variables _attaches them to document nodes
- any tags configured to fire on 'pageLoad' fire (push data into dataLayer)
- DOM ready (any tags configured for 'DOM ready' fire)
- window loads (any tags configured for 'windowLoaded' fire )
- 'triggers' ('rules') wait attached to proper DOM nodes
User interacts with the document (page):
- events occur
- rules ('triggers') are evaluated
- rules trigger tags
- tags push events' info into dataLayer
Other thoughts
- Legalzoom uses Tealium for their tag management. GTM seems to have the advantage, but it comes down to preference/what the teams are familiar with. Here’s an in-depth analysis. (Also some good notes about how it works with CSS selectors and data layer variables.)