
As a data product manager, it's come to my attention that I really need to pay closer attention to Splunk.
I've heard it mentioned fairly often over the years. But my current role is the first time I've had an opportunity to work with it hands-on. And the opportunity is getting exciting.
Splunk captures and processes system data from multiple sources in a technology stack. Logs and stuff. It's popular in the world of big data, used by many of the data-proud technology companies. But I've always assumed it more of a DevOps, system-stability/performance/monitoring tool. While this has a direct impact on the user experience, systems-stuff has typically been someone else's responsibility.
Now, it's time for me to empower others with data from Splunk.
My number 1 question: How does Splunk work? (What's going on "Under the hood"?)
I ask this, because I want to know as much as I can about the data I'm looking at. When reviewing metrics, it's important to understand how those metrics are calculated. Are we looking a sample of the population, or real, hard numbers? How can these numbers be reconciled and validated? Is there anything lacking in our systems that causes Splunk's metrics to tabulate sub-optimally?
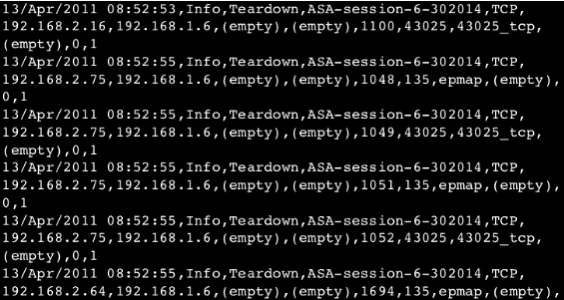
This is what machine data looks like:
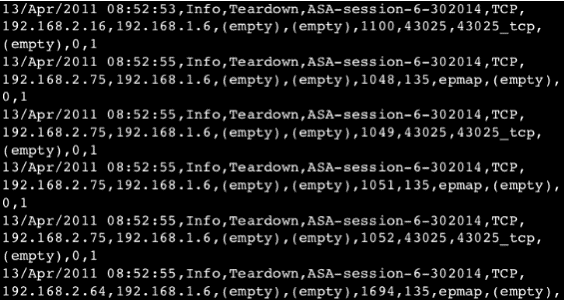
Sure, you can understand it if you look hard enough. But you can't paste this into a spread sheet to pivot and analyze. You can throw this in to Power BI or Tableau and get anything meaningful out of it. Imagine billions of rows of data similar to this, but not even exactly this--how would you even approach the problem? That's where Splunk comes in. Splunk will process this data for you, making it searchable, traceable, and correlatable.
How does Splunk do this? This question is a bit more difficult to find a reasonable answer. But it seems like it was written in C++ with a bunch of Python for the data processing. It's highly scalable, and can be architected to efficiently process petabytes of data a day. Seems similar to how Hadoop YARN manages clusters + map-reduce…stuff I'm only beginning to learning about at an architectural level.
There's a lot more to say about "how" this works. But I think I'll need to come back to this...
What does it take to set up and maintain Splunk? Does it take any extra effort on behalf of the development teams?
Splunk was already set up when I got here. But it's important for me to understand what it takes to support and maintain it.
…seems this is a very involved topic. Saving it for another day.
What is Domino's Pizza doing with Splunk?
- Interactive maps
- Shows all orders on a map in real-time
- Payment Process
- Analyzed the sped of different payment modes
- Determined error-free payment modes
- Real-time Feedback
- Employees constantly see what customers are saying
- Helped employees understand customer expectations
- Promotional Support
- Real-time promotion impact analyzed (vs lagging indicators, 1 day reports)
- Dashboard
- Used to keep score and set targets
- Compare performance with previous periods
- Performance Monitor
- Performance of systems such as POS